|
级别 |
最少盘数 |
安全性 |
性能 |
适用范围 |
|
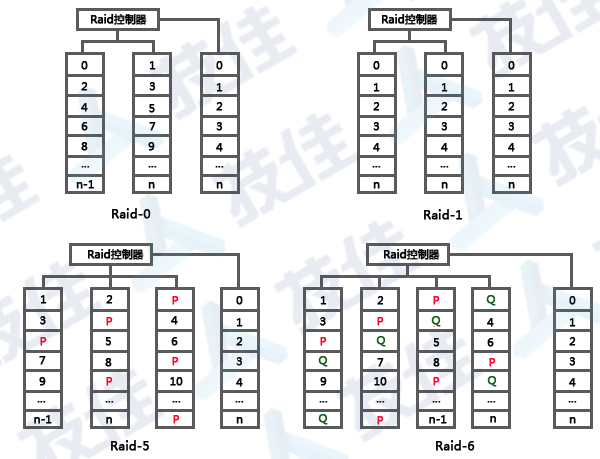
Raid-0 |
2 |
★ |
★★★★ |
Raid-0提供极佳的读写性能,磁盘利用率很高,但未提供任何冗余手段,任何一块成员盘故障,都会导致Raid失效,数据丢失,它在所有阵列模式中,安全性最差。 适用于对存储速度和容量要求较高,但数据重要性较低的企业和个人,例如婚纱影楼等。 |
|
Raid-1 |
仅可2块 |
★★★★★ |
★ |
Raid-1俗称镜像,两块成员盘同步进行操作,其中一块出现故障,不影响数据安全,但其性能和磁盘利用率最低,适用于存储极为重要的数据,例如企业财务数据、网站数据库等。 |
|
Raid-5 |
3 |
★★★ |
★★★★ |
Raid-5是最常用的一种阵列模式,它提供了一组冗余信息(P校验-校验值通过成员盘异或运算得出),允许其中一块成员盘掉线而不影响阵列的正常运行,同时兼顾了阵列的容量与性能,这使得Raid-5适用范围非常广,广泛应用于企业、政府、军队的大型存储中。 |
|
Raid-6 |
4 |
★★★★ |
★★★ |
Raid-6是Raid-5的加强版,它提供了两组冗余信息(P、 Q校验),最多允许两块成员盘掉线,安全性更高,当性能比Raid-5稍差,适用于对安全性要求更高的行业。 |
|
HP双循环 |
3 |
★★★ |
★★★★ |
惠普双循环是惠普服务器上特有的一种阵列模式,其整体为Raid-5(或Raid-6),但在Raid-5(Raid-6)下又包含了Raid-4,提供了一组冗余信息,其性能及安全性与单纯的Raid-5(Raid-6)相差不多,只搭载在惠普服务器上。 |
|
JBod/Big |
2 |
★★ |
★★ |
严格意义上说,JBod不是一种阵列模式,它仅将几块硬盘首尾相连,所以不存在条带、循环方向等Raid特性,容量为所有成员盘相加,这种阵列模式由于性能和安全性均不佳,在实际中较少被采用。 |
|
|
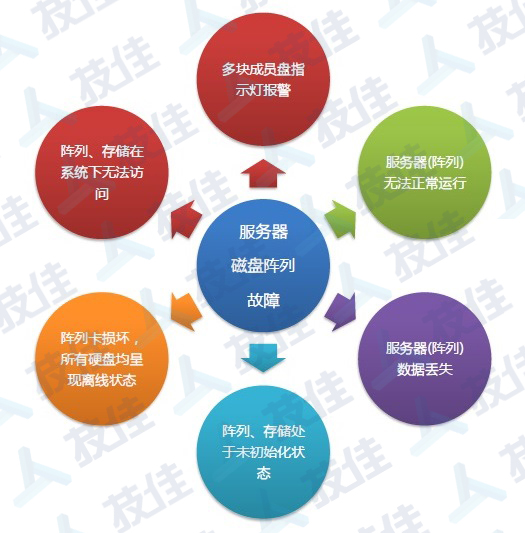
故障原因 |
故障表现 |
|
1 |
逻辑故障 |
1. 阵列中部分数据丢失或数据无法正常打开(文件系统损坏或文件结构破坏) 2. 阵列中某种格式(Office文档、压缩文件)无法正常打开(病毒破坏特定文件) 3. 在系统下,阵列未初始化(MBR损坏或分区表故障) 4. 阵列卷无法打开或提示格式化(文件系统损坏) 5. 误将阵列中一块多多块硬盘进行格式化操作 6. Raid重建(将Raid-1重建为Raid-0或反操作,将Raid-5重建为Raid-0或反操作等) |
|
2 |
成员盘物理故障 |
1. 多块成员盘指示灯报警 2. Raid管理器中多块硬盘离线或丢失 3. 阵列从系统下丢失并无法访问 4. 阵列呈现未初始化状态 5. 阵列重启后无法正常启动 6. 阵列同步过程中又有其它成员盘离线 |
|
3 |
阵列卡损坏 |
1. 阵列信息丢失,所有硬盘均呈现离线状态 2. 阵列在系统下无法识别 3. 无法进入Raid管理界面或查看Raid信息时死机 |
|
4 |
不恰当的阵列扩容 |
1. 多块成员盘指示灯报警 2. 阵列呈现未初始化状态,无法正常访问 3. 扩容后容量不正常,或发生卷丢失 4. 扩容后部分或全部文件丢失 |
|
5 |
盘序标记错误 |
1. 阵列无法正常启动 2. 在Raid管理中,阵列呈现未初始化状态 |
|
1 |
勤检查,多查看。定期查看阵列运行状态,及时发现不正常现象,并排除; |
|
2 |
阵列出现故障后,立即对阵列进行断电操作,切忌做重新创建、强制上线、强制重建等操作; |
|
3 |
非专业人事切忌对Raid模块进行拆卸、更换等操作 |
|
4 |
当对阵列硬盘进行清尘时,需提前标记盘序,避免由于盘序错乱导致Raid信息丢失。 |
|
5 |
任何容灾措施都不可能万无一失,定期对阵列内的重要数据进行备份,勤备份是防止数据丢失唯一行之有效的途径。 |
|
6 |
及时求助正规专业的数据恢复机构,阵列是可以用钱买到的,但数据是无价的,在进行阵列修复前,切记先将数据完整恢复。 |